
A Deep Dive into the AI algorithms that companies like Facebook and Google have built their business around.
As recently as May 2019 Facebook open-sourced some of their recommendation approaches and introduced the DLRM (Deep-learning Recommendation Model). This blog post is meant to explain how and why DLRM and other modern recommendation approaches work so well. Read More
Monthly Archives: January 2021
InShort: Occlusion Analysis for Explaining DNNs
There are abundantly many explanation methods for explaining deep neural networks (DNNs), each with its advantages and disadvantages. In most cases, we are interested in local explanation methods, i.e. explanations of the network’s output for a particular input, because DNNs tend to be too complex to be explained globally (independent of an input).
… In this short article, I will present one fundamental attribution technique: occlusion analysis. The basic concept is as simple as they come: For every input dimension of an input x, we evaluate the model with that dimension missing, and observe how the output changes. Read More
Evolvable neural units that can mimic the brain’s synaptic plasticity
Machine learning techniques are designed to mathematically emulate the functions and structure of neurons and neural networks in the brain. However, biological neurons are very complex, which makes artificially replicating them particularly challenging.
Researchers at Korea University have recently tried to reproduce the complexity of biological neurons more effectively by approximating the function of individual neurons and synapses. Their paper, published in Nature Machine Intelligence, introduces a network of evolvable neural units (ENUs) that can adapt to mimic specific neurons and mechanisms of synaptic plasticity. Read More
Artificial intelligence researchers rank the top A.I. labs worldwide
Artificial intelligence researchers don’t like it when you ask them to name the top AI labs in the world, possibly because it’s so hard to answer.
U.S. Big Tech — Google, Facebook, Amazon, Apple and Microsoft — have all set up dedicated AI labs over the last decade.
There’s also DeepMind, which is owned by Google parent company Alphabet, and OpenAI, which counts Elon Musk as a founding investor.
… “Reputationally, there is a good argument to say DeepMind, OpenAI, and FAIR (Facebook AI research]) are the top three,” according to Mark Riedl, associate professor at the Georgia Tech School of Interactive Computing. Read More
Should a self-driving car kill the baby or the grandma? Depends on where you’re from.
The infamous “trolley problem” was put to millions of people in a global study, revealing how much ethics diverge across cultures.
In 2014 researchers at the MIT Media Lab designed an experiment called Moral Machine. The idea was to create a game-like platform that would crowdsource people’s decisions on how self-driving cars should prioritize lives in different variations of the “trolley problem.” In the process, the data generated would provide insight into the collective ethical priorities of different cultures.
… A new paper published in Nature presents the analysis of that data and reveals how much cross-cultural ethics diverge on the basis of culture, economics, and geographic location. Read More
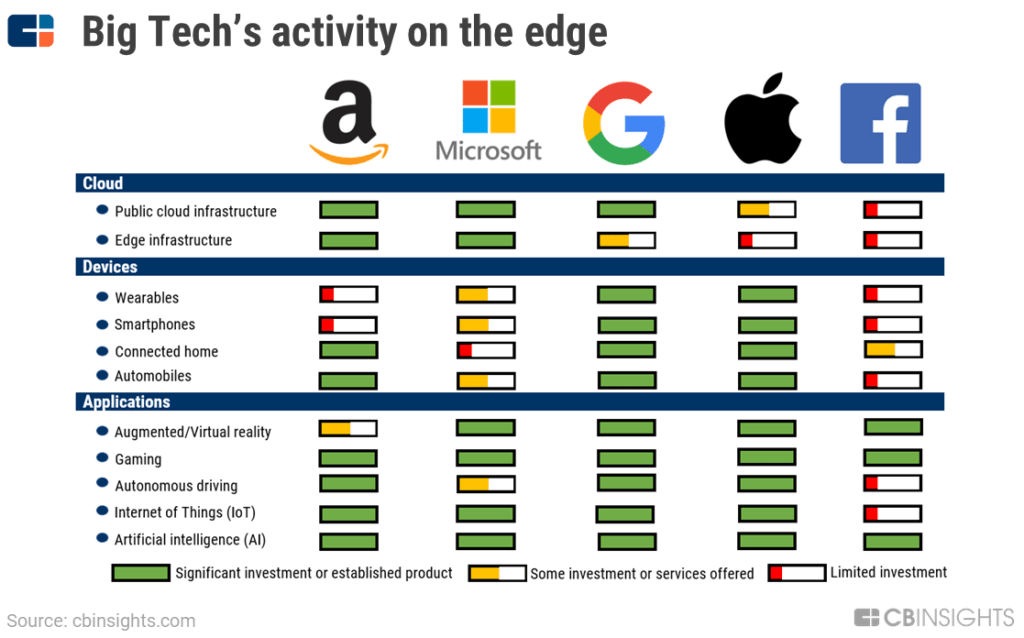
Big Tech In Edge Computing
Companies are addressing issues related to language with AI
Artificial intelligence (AI) has been impacting not only human lives but also various industries. Its tools, like deep learning, can increasingly teach themselves how to perform complex tasks. Besides, self-driving cars are about to hit the streets, and diseases are being treated using AI technology.
Yet despite these impressive advances, one fundamental capability remains elusive: language. Systems like Siri, Amazon’s Alexa and IBM’s Watson can follow simple spoken or typed commands and answer basic questions, but they can’t hold a conversation and have no real understanding of the words they use. If artificial intelligence is to be truly transformative, this must change. Read More
The past, present and future of deep learning
TLDR; In this blog, you’ll be learning the theoretical aspects of deep learning (DL) and how it has evolved, right from the study of the human brain to building complex algorithms. Next, you’ll be looking at a few pieces of research that have been carried by renowned deep learning folks who have then sown the sapling in the fields of DL which has now grown into a gigantic tree. Lastly, you’ll be introduced to the applications and the areas where deep learning has set a strong foothold. Read More
Gun Detection AI is Being Trained With Homemade ‘Active Shooter’ Videos
Companies are using bizarre methods to create algorithms that automatically detect weapons. AI ethicists worry they will lead to more police violence.
In Huntsville, Alabama, there is a room with green walls and a green ceiling. Dangling down the center is a fishing line attached to a motor mounted to the ceiling, which moves a procession of guns tied to the translucent line.
The staff at Arcarithm bought each of the 10 best-selling firearm models in the U.S.: Rugers, Glocks, Sig Sauers. Pistols and long guns are dangled from the line. The motor rotates them around the room, helping a camera mounted to a mobile platform photograph them from multiple angles. “ Read More
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of super-vision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision.We demonstrate that the simple pretraining task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pretraining, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training.For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. Read More
#image-recognition, #nlp