
Just because a business process can be automated, doesn’t necessarily mean it should be automated. And maybe — just maybe — there are components of business that are not better served with AI algorithms doing the job.
That’s a key takeaway after Zillow Group made the unexpected decision on Tuesday to shutter its home buying business — a painful move that will result in 2,000 employees losing their jobs, a $304 million third quarter write-down, a spiraling stock price (shares are down more than 18% today), and egg on the face of co-founder and CEO Rich Barton. Read More
Tag Archives: Accuracy
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
We identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets,1where for example 2916 label errors comprise 6% of the ImageNet validation set.Putative label errors are identified using confident learning algorithms and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Traditionally, machine learning practitioners choose which model to deploy based on test accuracy — our findings advise caution here, proposing that judging models over correctly labeled test sets maybe more useful, especially for noisy real-world datasets. Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data.For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. OnCIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by just 5%. Read More
A Study of Face Obfuscation in ImageNet
Face obfuscation (blurring, mosaicing, etc.) has been shown to be effective for privacy protection; nevertheless, object recognition research typically assumes access to complete, unobfuscated images. In this paper, we explore the effects of face obfuscation on the popular ImageNet challenge visual recognition benchmark. Most categories in the ImageNet challenge are not people categories; however, many incidental people appear in the images, and their privacy is a concern. We first annotate faces in the dataset. Then we demonstrate that face blurring—a typical obfuscation technique—has minimal impact on the accuracy of recognition models. Concretely, we benchmark multiple deep neural networks on face-blurred images and observe that the overall recognition accuracy drops only slightly (≤0.68%). Further,we experiment with transfer learning to 4 downstream tasks (object recognition, scene recognition, face attribute classification, and object detection) and show that features learned on face-blurred images are equally transferable. Our work demonstrates the feasibility of privacy-aware visual recognition, improves the highly-used ImageNet challenge benchmark,and suggests an important path for future visual datasets. Read More
The Lottery Ticket Hypothesis That Shocked The World
In machine learning, bigger may not always be better. As the datasets and the machine learning models keep expanding, researchers are racing to build state-of-the-art benchmarks. However, larger models can be detrimental to the budget and the environment.
Over time, researchers have developed several ways to shrink the deep learning models while optimizing training datasets. In particular, three techniques–pruning, quantization, and transfer learning–have been instrumental in making models run faster and more accurately at lesser compute power.
In a 2019 study, Lottery Ticket Hypothesis, MIT researchers showed it was possible to remove a few unnecessary connections in neural networks and still achieve good or even better accuracy. Read More
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
We identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets,2where for example 2916 label errors comprise 6% of the ImageNet validation set.Putative label errors are identified using confident learning algorithms and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Traditionally, machine learning practitioners choose which model to deploy based on test accuracy — our findings advise caution here, proposing that judging models over correctly labeled test sets maybe more useful, especially for noisy real-world datasets. Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data.For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. OnCIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by just 5%. Read More
#accuracy, #biasA New Artificial Intelligence Makes Mistakes—on Purpose
A chess program that learns from human error might be better at working with people or negotiating with them.
It took about 50 years for computers to eviscerate humans in the venerable game of chess. A standard smartphone can now play the kind of moves that make a grandmaster’s head spin. But one artificial intelligence program is taking a few steps backward, to appreciate how average humans play—blunders and all.
The AI chess program, known as Maia, uses the kind of cutting-edge AI behind the best superhuman chess-playing programs. But instead of learning how to destroy an opponent on the board, Maia focuses on predicting human moves, including the mistakes they make. Read More
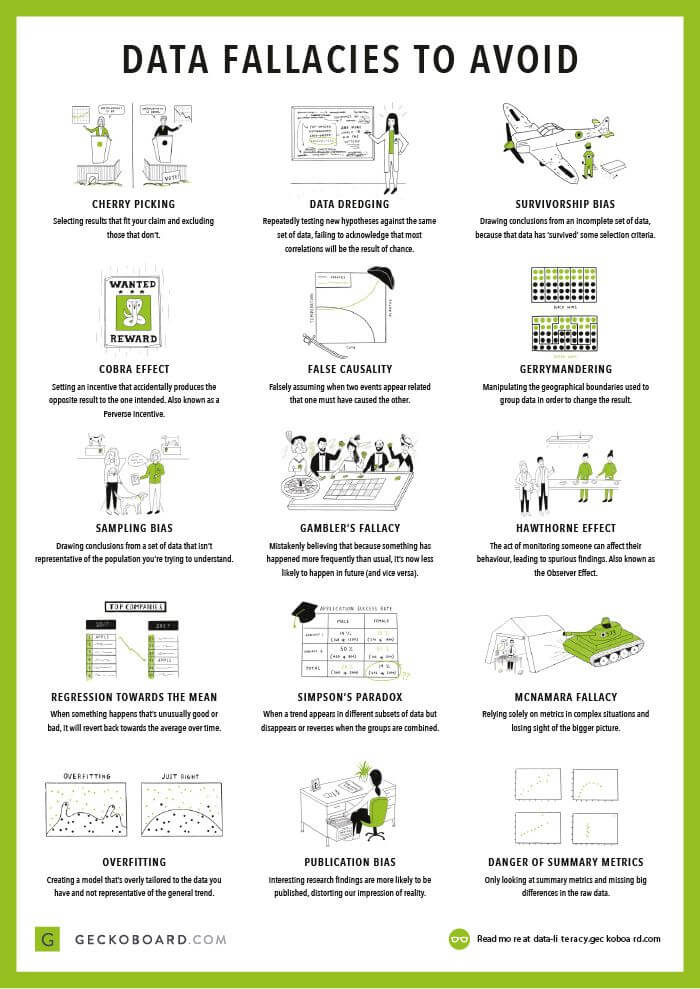
Data fallacies
Statistical fallacies are common tricks data can play on you, which lead to mistakes in data interpretation and analysis. Explore some common fallacies, with real-life examples, and find out how you can avoid them. Read More
Can Your AI Differentiate Cats from Covid-19?Sample Efficient Uncertainty Estimation for Deep Learning Safety
Deep Neural Networks (DNNs) are known to make highly overconfident predictions on Out-of-Distribution data. Recent research has shown that uncertainty-aware models, such as, Bayesian Neural Network (BNNs) and Deep Ensembles,are less susceptible to this issue. However research in this area has been largely confined to the big data setting. In this work, we show that even state-of-the-art BNNs and Ensemble models tend to make overconfident predictions when the amount of training data is insufficient. This is especially concerning for emerging applications in physical sciences and healthcare where over-confident and inaccurate predictions can lead to disastrous consequences. To address the issue of accurate uncertainty (or confidence) estimation in the small-data regime, we propose a probabilistic generalization of the popular sample-efficient non-parametric kNN approach. We demonstrate the usefulness of the proposed approach on a real-world application of COVID-19 diagnosis from chest X-Rays by (a) highlighting surprising failures of existing techniques, and (b) achieving superior uncertainty quantification as compared to state-of-the-art. Read More
Failure Modes in Machine Learning
In the last two years, more than 200 papers have been written on how Machine Learning (ML) can fail because of adversarial attacks on the algorithms and data; this number balloons if we were to incorporate non-adversarial failure modes. The spate of papers has made it difficult for ML practitioners, let alone engineers, lawyers and policymakers, to keep up with the attacks against and defenses of ML systems. However, as these systems become more pervasive, the need to understand how they fail, whether by the hand of an adversary or due to the inherent design of a system, will only become more pressing. The purpose of this document is to jointly tabulate both the of these failure modes in a single place.
— Intentional failures wherein the failure is caused by an active adversary attempting to subvert the system to attain her goals – either to misclassify the result, infer private training data, or to steal the underlying algorithm.
— Unintentional failures wherein the failure is because an ML system produces a formally correct but completely unsafe outcome.
Read More
Questioning The Long-Term Importance Of Big Data In AI
No asset is more prized in today’s digital economy than data. It has become widespread to the point of cliche to refer to data as “the new oil.” As one recent Economist headline put it, data is “the world’s most valuable resource.”
Data is so highly valued today because of the essential role it plays in powering machine learning and artificial intelligence solutions. Training an AI system to function effectively—from Netflix’s recommendation engine to Google’s self-driving cars—requires massive troves of data.
The result has been an obsession with bigger and bigger data. He with the most data can build the best AI, according to the prevailing wisdom. Read More
