
We identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets,2where for example 2916 label errors comprise 6% of the ImageNet validation set.Putative label errors are identified using confident learning algorithms and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Traditionally, machine learning practitioners choose which model to deploy based on test accuracy — our findings advise caution here, proposing that judging models over correctly labeled test sets maybe more useful, especially for noisy real-world datasets. Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data.For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. OnCIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by just 5%. Read More
#accuracy, #biasTag Archives: Bias
How can we keep algorithmic racism out of Canadian health care’s AI toolkit?
Chances are that artificial intelligence is already helping a hospital near you to diagnose patients or monitor surgeries. But health care has a long, ugly history of racial biases that prevent everyone from getting the best treatment
In health care, the promise of artificial intelligence is alluring: With the help of big data sets and algorithms, AI can aid difficult decisions, like triaging patients and determiningdiagnoses. And since AI leans on statistics rather than human interpretation, the idea is that it’s neutral – it treats everyone in a given data set equally.
But what if it doesn’t? Read More
Re-imagining Algorithmic Fairness in India and Beyond
Conventional algorithmic fairness is West-centric, as seen in its sub-groups, values, and optimisations. In this paper, we de-center algorithmic fairness and analyse AI power in India. Based on 36 qualitative interviews and a discourse analysis of algorithmic deployments in India, we find that several assumptions of algorithmic fairness are challenged in India. We find that data is not always reliable due to socio-economic factors, users are given third world treatment by ML makers, and AI signifies unquestioning aspiration. We contend that localising model fairness alone can be window dressing in India, where the distance between models and oppressed communities is large. Instead, we re-imagine algorithmic fairness in India and provide a roadmap to re-contextualise data and models, empower oppressed communities, and enable Fair-ML ecosystems. Read More
Data fallacies
Statistical fallacies are common tricks data can play on you, which lead to mistakes in data interpretation and analysis. Explore some common fallacies, with real-life examples, and find out how you can avoid them. Read More
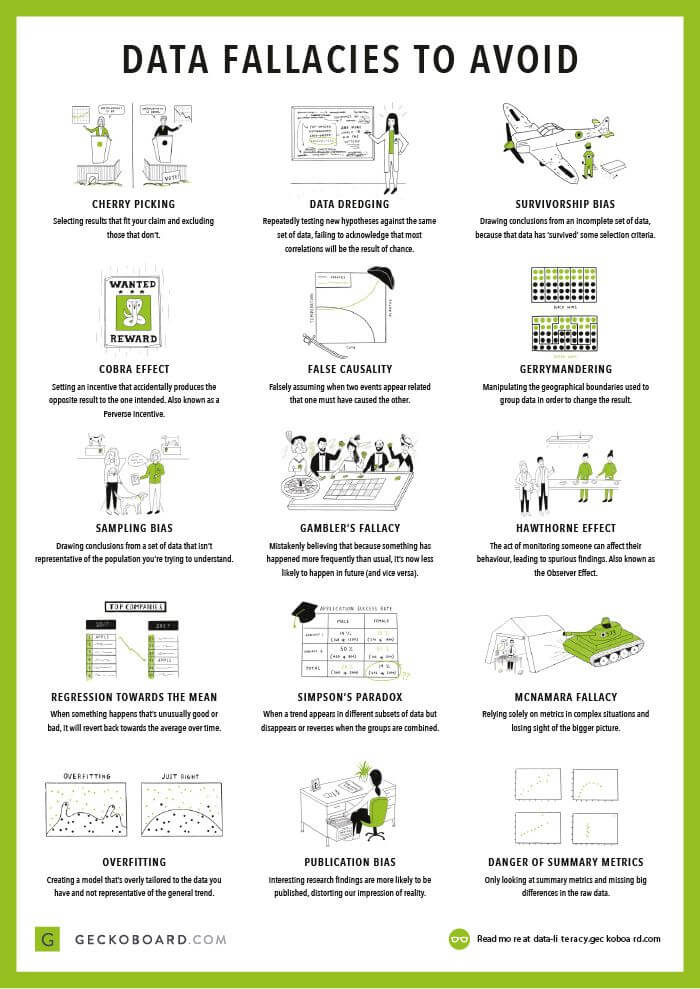
Image Representations Learned With Unsupervised Pre-Training Contain Human-like Biases
Recent advances in machine learning leverage massive datasets of unlabeled images from the web to learn general-purpose image representations for tasks from image classification to face recognition. But do unsupervised computer vision models automatically learn implicit patterns and embed social biases that could have harmful downstream effects? We develop a novel method for quantifying biased associations between representations of social concepts and attributes in images. We find that state-of-the-art unsupervised models trained on ImageNet, a popular benchmark image dataset curated from internet images, automatically learn racial, gender, and intersectional biases. We replicate 8 previously documented human biases from social psychology, from the innocuous, as with insects and flowers, to the potentially harmful, as with race and gender. Our results closely match three hypotheses about intersectional bias from social psychology. For the first time in unsupervised computer vision, we also quantify implicit human biases about weight, disabilities, and several ethnicities. When compared with statistical patterns in online image datasets, our findings suggest that machine learning models can automatically learn bias from the way people are stereotypically portrayed on the web. Read More
#biasCharacterizing Bias in Compressed Models
The popularity and widespread use of pruning and quantization is driven by the severe resource constraints of deploying deep neural networks to environments with strict latency, memory and energy requirements. These techniques achieve high levels of compression with negligible impact on top-line metrics (top-1 and top-5 accuracy). However, overall accuracy hides disproportionately high errors on a small subset of examples; we call this subset Compression Identified Exemplars (CIE). We further establish that for CIE examples, compression amplifies existing algorithmic bias. Pruning disproportionately impacts performance on underrepresented features, which often coincides with considerations of fairness. Given that CIE is a relatively small subset but a great contributor of error in the model, we propose its use as a human-in-the-loop auditing tool to surface a tractable subset of the dataset for further inspection or annotation by a domain expert. We provide qualitative and quantitative support that CIE surfaces the most challenging examples in the data distribution for human-in-the-loop auditing. Read More
#biasWe must stop militant liberals from politicizing artificial intelligence
What do you do if decisions that used to be made by humans, with all their biases, start being made by algorithms that are mathematically incapable of bias? If you’re rational, you should celebrate. If you’re a militant liberal, you recognize this development for the mortal threat it is, and scramble to take back control.
You can see this unfolding at AI conferences. Last week I attended the 2020 edition of NeurIPS, the leading international machine learning conference. What started as a small gathering now brings together enough people to fill a sports arena. This year, for the first time, NeurIPS required most papers to include a ‘broader impacts’ statement, and to be subject to review by an ethics board. Every paper describing how to speed up an algorithm, for example, now needs to have a section on the social goods and evils of this obscure technical advance. ‘Regardless of scientific quality or contribution,’ stated the call for papers, ‘a submission may be rejected for… including methods, applications, or data that create or reinforce unfair bias.’ Read More
Google Reveals Major Hidden Weakness In Machine Learning
In recent years, machines have become almost as good as humans, and sometimes better, in a wide range of abilities — for example, object recognition, natural language processing and diagnoses based on medical images.
And yet machines trained in this way still make mistakes that humans would never fall for.
… So computer scientists are desperate to understand the limitations of machine learning in more detail. Now a team made up largely of Google computer engineers have identified an entirely new weakness at the heart of the machine learning process that leads to these problems. Read More
Read the paper
When AI Sees a Man, It Thinks ‘Official.’ A Woman? ‘Smile’
A new paper renews concerns about bias in image recognition services offered by Google, Microsoft, and Amazon.
Men often judge women by their appearance. Turns out, computers do too.
When US and European researchers fed pictures of congressmembers to Google’s cloud image recognition service, the service applied three times as many annotations related to physical appearance to photos of women as it did to men.
…“It results in women receiving a lower status stereotype: That women are there to look pretty and men are business leaders.” Read More
AI Camera Mistakenly Tracks Referee’s Bald Head Instead of Soccer Ball
As the world starts to slowly cede control of everything to artificial intelligence, there’s bound to be some growing pains. When a Scottish soccer team upgraded their stadium with live-streamed games courtesy of a ball-tracking, AI-powered camera, they failed to realize that, to a computer, a referee with a shaved and/or bald head would be nearly indistinguishable from a soccer ball. Read More
