
Tag Archives: Deep Learning
Building Better Deep Learning Requires New Approaches Not Just Bigger Data
In its rush to solve all the world’s problems through deep learning, Silicon Valley is increasingly embracing the idea of AI as a universal solver that can be rapidly adapted to any problem in any domain simply by taking a stock algorithm and feeding it relevant training data. The problem with this assumption is that today’s deep learning systems are little more than correlative pattern extractors that search large datasets for basic patterns and encode them into software. While impressive compared to the standards of previous eras, these systems are still extraordinarily limited, capable only of identifying simplistic correlations rather than actually semantically understanding their problem domain. In turn, the hand-coded era’s focus on domain expertise, ethnographic codification and deeply understanding a problem domain has given way to parachute programming in which deep learning specialists take an off-the-shelf algorithm, shove in a pile of training data, dump out the resulting model and move on to the next problem. Truly advancing the state of deep learning and way in which companies make use of it will require a return to the previous era’s focus on understanding problems rather than merely churning canned models off assembly lines. Read More
The Power of Self-Learning Systems
AI Codes its Own ‘AI Child’ – AutoML
How the Artificial-Intelligence Program AlphaZero Mastered Its Games
A few weeks ago, a group of researchers from Google’s artificial-intelligence subsidiary, DeepMind, published a paper in the journal Science that described an A.I. for playing games. While their system is general-purpose enough to work for many two-person games, the researchers had adapted it specifically for Go, chess, and shogi (“Japanese chess”); it was given no knowledge beyond the rules of each game. At first it made random moves. Then it started learning through self-play. Over the course of nine hours, the chess version of the program played forty-four million games against itself on a massive cluster of specialized Google hardware. After two hours, it began performing better than human players; after four, it was beating the best chess engine in the world.The best of The New Yorker, in your in-boxReporting, commentary, culture, and humor. Sign up for our newsletters now.
The program, called AlphaZero, descends from AlphaGo, an A.I. that became known for defeating Lee Sedol, the world’s best Go player, in March of 2016. Sedol’s defeat was a stunning upset. In “AlphaGo,” a documentary released earlier this year on Netflix, the filmmakers follow both the team that developed the A.I. and its human opponents, who have devoted their lives to the game. We watch as these humans experience the stages of a new kind of grief. At first, they don’t see how they can lose to a machine: “I believe that human intuition is still too advanced for A.I. to have caught up,” Sedol says, the day before his five-game match with AlphaGo. Then, when the machine starts winning, a kind of panic sets in. In one particularly poignant moment, Sedol, under pressure after having lost his first game, gets up from the table and, leaving his clock running, walks outside for a cigarette. He looks out over the rooftops of Seoul. (On the Internet, more than fifty million people were watching the match.) Meanwhile, the A.I., unaware that its opponent has gone anywhere, plays a move that commentators called creative, surprising, and beautiful. In the end, Sedol lost, 1-4. Before there could be acceptance, there was depression. “I want to apologize for being so powerless,” he said in a press conference. Eventually, Sedol, along with the rest of the Go community, came to appreciate the machine. “I think this will bring a new paradigm to Go,” he said. Fan Hui, the European champion, agreed. “Maybe it can show humans something we’ve never discovered. Maybe it’s beautiful.” Read More
An All-Neural On-Device Speech Recognizer
In 2012, speech recognition research showed significant accuracy improvements with deep learning, leading to early adoption in products such as Google’s Voice Search. It was the beginning of a revolution in the field: each year, new architectures were developed that further increased quality, from deep neural networks (DNNs) to recurrent neural networks (RNNs), long short-term memory networks (LSTMs), convolutional networks (CNNs), and more. During this time, latency remained a prime focus — an automated assistant feels a lot more helpful when it responds quickly to requests.
Today, we’re happy to announce the rollout of an end-to-end, all-neural, on-device speech recognizer to power speech input in Gboard. In our recent paper, “Streaming End-to-End Speech Recognition for Mobile Devices“, we present a model trained using RNN transducer (RNN-T) technology that is compact enough to reside on a phone. This means no more network latency or spottiness — the new recognizer is always available, even when you are offline. The model works at the character level, so that as you speak, it outputs words character-by-character, just as if someone was typing out what you say in real-time, and exactly as you’d expect from a keyboard dictation system. Read More
Streaming End-to-End Speech Recognition for Mobile Devices
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context(e.g., contact lists); and above all, they must be extremely accurate.In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories. Read More
The new Artificial Intelligence frontier of VFX
If there’s a buzz phrase right now in visual effects, it’s “machine learning.” In fact, there are three: machine learning, deep learning and artificial intelligence (A.I.). Each phrase tends to be used interchangeably to mean the new wave of smart software solutions in VFX, computer graphics and animation that lean on A.I. techniques.
Already, research in machine and deep learning has helped introduce both automation and more physically-based results in computer graphics, mostly in areas such as camera tracking, simulations, rendering, motion capture, character animation, image processing, rotoscoping and compositing. Read More
What is the difference between AI, machine learning and deep learning?
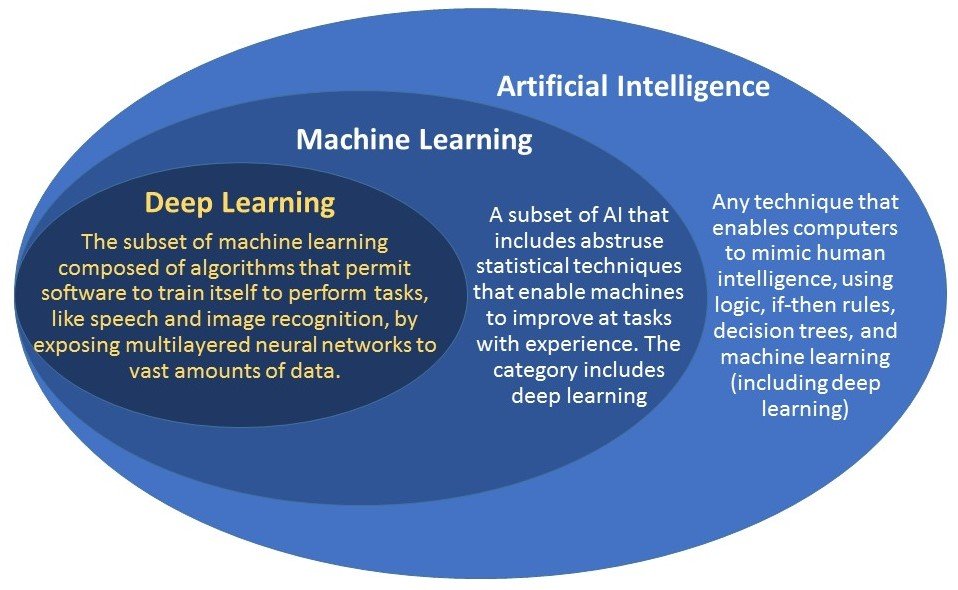
You can think of artificial intelligence (AI), machine learning and deep learning as a set of a matryoshka doll, also known as a Russian nesting doll. Deep learning is a subset of machine learning, which is a subset of AI. Read More
Facial recognition: Apple, Amazon, Google and the race for your face
Facial recognition is a blossoming field of technology that is at once exciting and problematic. If you’ve ever unlocked your iPhone ($1,000 at Amazon) by looking at it, or asked Facebook or Google to go through an unsorted album and show you pictures of your kids, you’ve seen facial recognition in action. Whether you want it to or not, facial recognition (sometimes called simply “face recognition”) is poised to play an ever-growing role in your life. Read More
