
When Google announced it was rolling out its artificial-intelligence-powered search feature earlier this month, the company promised that “Google will do the googling for you.” The new feature, called AI Overviews, provides brief, AI-generated summaries highlighting key information and links on top of search results.
Unfortunately, AI systems are inherently unreliable. Within days of AI Overviews’ release in the US, users were sharing examples of responses that were strange at best. It suggested that users add glue to pizza or eat at least one small rock a day, and that former US president Andrew Johnson earned university degrees between 1947 and 2012, despite dying in 1875.
On Thursday, Liz Reid, head of Google Search, announced that the company has been making technical improvements to the system to make it less likely to generate incorrect answers, including better detection mechanisms for nonsensical queries. It is also limiting the inclusion of satirical, humorous, and user-generated content in responses, since such material could result in misleading advice.
But why is AI Overviews returning unreliable, potentially dangerous information? And what, if anything, can be done to fix it? — Read More
Tag Archives: Explainability
Anthropic tricked Claude into thinking it was the Golden Gate Bridge (and other glimpses into the mysterious AI brain)
AI models are mysterious: They spit out answers, but there’s no real way to know the “thinking” behind their responses. This is because their brains operate on a fundamentally different level than ours — they process long lists of neurons linked to numerous different concepts — so we simply can’t comprehend their line of thought.
But now, for the first time, researchers have been able to get a glimpse into the inner workings of the AI mind. The team at Anthropic has revealed how it is using “dictionary learning” on Claude Sonnet to uncover pathways in the model’s brain that are activated by different topics — from people, places and emotions to scientific concepts and things even more abstract. — Read More
Read The Paper
Large language models can do jaw-dropping things. But nobody knows exactly why.
Two years ago, Yuri Burda and Harri Edwards, researchers at the San Francisco–based firm OpenAI, were trying to find out what it would take to get a language model to do basic arithmetic. They wanted to know how many examples of adding up two numbers the model needed to see before it was able to add up any two numbers they gave it. At first, things didn’t go too well. The models memorized the sums they saw but failed to solve new ones.
By accident, Burda and Edwards left some of their experiments running far longer than they meant to—days rather than hours. The models were shown the example sums over and over again, way past the point when the researchers would otherwise have called it quits. But when the pair at last came back, they were surprised to find that the experiments had worked. They’d trained a language model to add two numbers—it had just taken a lot more time than anybody thought it should.
Curious about what was going on, Burda and Edwards teamed up with colleagues to study the phenomenon. They found that in certain cases, models could seemingly fail to learn a task and then all of a sudden just get it, as if a lightbulb had switched on. This wasn’t how deep learning was supposed to work. They called the behavior grokking. — Read More
Double Descent Paper
Orca 2: Teaching Small Language Models How to Reason
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs’ reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at this http URL to support research on the development, evaluation, and alignment of smaller LMs. — Read More
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation signals from shallow LFM outputs; small scale homogeneous training data; and most notably a lack of rigorous evaluation resulting in overestimating the small model’s capability as they tend to learn to imitate the style, but not the reasoning process of LFMs. To address these challenges, we develop Orca (We are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA’s release policy to be published at this https URL), a 13-billion parameter model that learns to imitate the reasoning process of LFMs. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. To promote this progressive learning, we tap into large-scale and diverse imitation data with judicious sampling and selection. Orca surpasses conventional state-of-the-art instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big-Bench Hard (BBH) and 42% on AGIEval. Moreover, Orca reaches parity with ChatGPT on the BBH benchmark and shows competitive performance (4 pts gap with optimized system message) in professional and academic examinations like the SAT, LSAT, GRE, and GMAT, both in zero-shot settings without CoT; while trailing behind GPT-4. Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills. — Read More
Explainable AI: Making the Black Box Transparent
Explainable AI (XAI) has been gaining popularity among tech enthusiasts, data scientists, and software engineers in a world where AI is becoming more prevalent.
In a world increasingly driven by artificial intelligence, a new term has been capturing the attention of tech enthusiasts, data scientists, and software engineers alike: Explainable AI (XAI). But what exactly is it? According to DARPA, Explainable AI refers to artificial intelligence systems whose actions can be understood by human experts. In other words, XAI aims to shed light on the inner workings of complex AI models, making them more transparent and less of a ‘black box.’ — Read More
Explainable Artificial Intelligence (XAI)
The Explainable AI (XAI) program aims to create a suite of machine learning techniques that:
- Produce more explainable models, while maintaining a high level of learning performance (prediction accuracy); and
- Enable human users to understand, appropriately trust, and effectively manage the emerging generation of artificially intelligent partners.
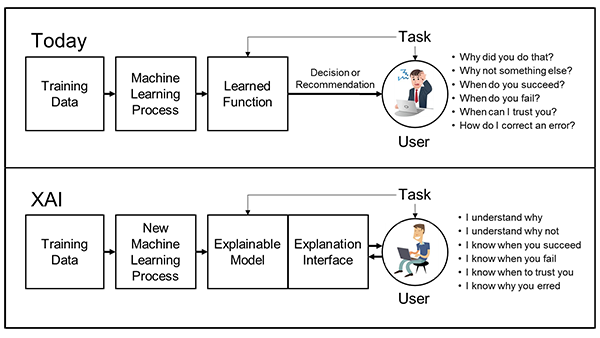
XAI: Learning Fairness with Interpretable Machine
Scientists modify Pepper the robot so they can now ‘think out loud
Evaluating Explainable Artificial Intelligence Methods for Multi-label Deep Learning Classification Tasks in Remote Sensing
Although deep neural networks hold the state-of-the-art in several remote sensing tasks, their black-box operation hinders the understanding of their decisions, concealing any bias and other shortcomings in datasets and model performance. To this end, we have applied explainable artificial intelligence (XAI) methods in remote sensing multi-label classification tasks towards producing human-interpretable explanations and improve transparency. In particular, we developed deep learning models with state-of-the-art performance in the benchmark BigEarthNet and SEN12MS datasets. Ten XAI methods were employed towards understanding and interpreting models’ predictions, along with quantitative metrics to assess and compare their performance. Numerous experiments were performed to assess the overall performance of XAI methods for straightforward prediction cases, competing multiple labels, as well as misclassification cases. According to our findings, Occlusion, Grad-CAM and Lime were the most interpretable and reliable XAI methods. However, none delivers high-resolution outputs, while apart from Grad-CAM, both Lime and Occlusion are computationally expensive. We also highlight different aspects of XAI performance and elaborate with insights on black-box decisions in order to improve transparency, understand their behavior and reveal, as well, datasets’ particularities. Read More
