
Techniques such as ensembling and distillation promise model quality improvements when paired with almost any base model. However, due to increased testtime cost (for ensembles) and increased complexity of the training pipeline (for distillation), these techniques are challenging to use in industrial settings. In this paper we explore a variant of distillation which is relatively straightforward to use as it does not require a complicated multi-stage setup or many new hyperparameters. Our first claim is that online distillation enables us to use extra parallelism to fit very large datasets about twice as fast. Crucially, we can still speed up training even after we have already reached the point at which additional parallelism provides no benefit for synchronous or asynchronous stochastic gradient descent. Two neural networks trained on disjoint subsets of the data can share knowledge by encouraging each model to agree with the predictions the other model would have made. These predictions can come from a stale version of the other model so they can be safely computed using weights that only rarely get transmitted. Our second claim is that online distillation is a cost-effective way to make the exact predictions of a model dramatically more reproducible. We support our claims using experiments on the Criteo Display Ad Challenge dataset, ImageNet, and the largest to-date dataset used for neural language modeling, containing 6 × 1011 tokens and based on the Common Crawl repository of web data. Read More
Tag Archives: Machine Learning
Distributed Deep Learning, Part 1: An Introduction to Distributed Training of Neural Networks
Modern neurl network architectures trained on large data sets can obtain impressive performance across a wide variety of domains, from speech and image recognition, to natural language processing to industry-focused applications such as fraud detection and recommendation systems. But training these neural network models is computationally demanding. Although in recent years significant advances have been made in GPU hardware, network architectures and training methods, the fact remains that network training can take an impractically long time on a single machine. Fortunately, we are not restricted to a single machine: a significant amount of work and research has been conducted on enabling the efficient distributed training of neural networks. Read More
Multi-objective Evolutionary Federated Learning
Federated learning is an emerging technique used to prevent the leakage of private information. Unlike centralized learning that needs to collect data from users and store them collectively on a cloud server, federated learning makes it possible to learn a global model while the data are distributed on the users’ devices. However, compared with the traditional centralized approach, the federated setting consumes considerable communication resources of the clients, which is indispensable for updating global models and prevents this technique from being widely used. In this paper, we aim to optimize the structure o f the neural network models in federated learning using a multiobjective evolutionary algorithm to simultaneously minimize the communication costs and the global model test errors. A scalable method for encoding network connectivity is adapted to federated learning to enhance the efficiency in evolving deep neural networks. Experimental results on both multilayer perceptrons and convolutional neural networks indicate that the proposed optimization method is able to find optimized neural network models that can not only significantly reduce communication costs but also improve the learning performance of federated learning compared with the standard fully connected neural networks . Read More
An introduction to Federated Learning
Federated learning makes it possible to build machine learning systems without direct access to training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs.
This article is about the business case for federated learning. We’ll talk about how it works at a conceptual level, and then focus on the applications and use cases. Read More
Federated learning: distributed machine learning with data locality and privacy
We’re excited to release Federated Learning, the latest report and prototype from Cloudera Fast Forward Labs.
Federated learning makes it possible to build machine learning systems without direct access to training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs. Read More
Communication-Efficient Learning of Deep Networks from Decentralized Data
Modern mobile devices have access to a wealth of data suitable for learning models, which in turn can greatly improve the user experience on the device. For example, language models can improve speech recognition and text entry, and image models can automatically select good photos. However, this rich data is often privacy sensitive, large in quantity, or both, which may preclude logging to the data center and training there using conventional approaches. We advocate an alternative that leaves the training data distributed on the mobile devices, and learns a shared model by aggregating locally-computed updates. We term this decentralized approach Federated Learning. Read More
The new Artificial Intelligence frontier of VFX
If there’s a buzz phrase right now in visual effects, it’s “machine learning.” In fact, there are three: machine learning, deep learning and artificial intelligence (A.I.). Each phrase tends to be used interchangeably to mean the new wave of smart software solutions in VFX, computer graphics and animation that lean on A.I. techniques.
Already, research in machine and deep learning has helped introduce both automation and more physically-based results in computer graphics, mostly in areas such as camera tracking, simulations, rendering, motion capture, character animation, image processing, rotoscoping and compositing. Read More
What is the difference between AI, machine learning and deep learning?
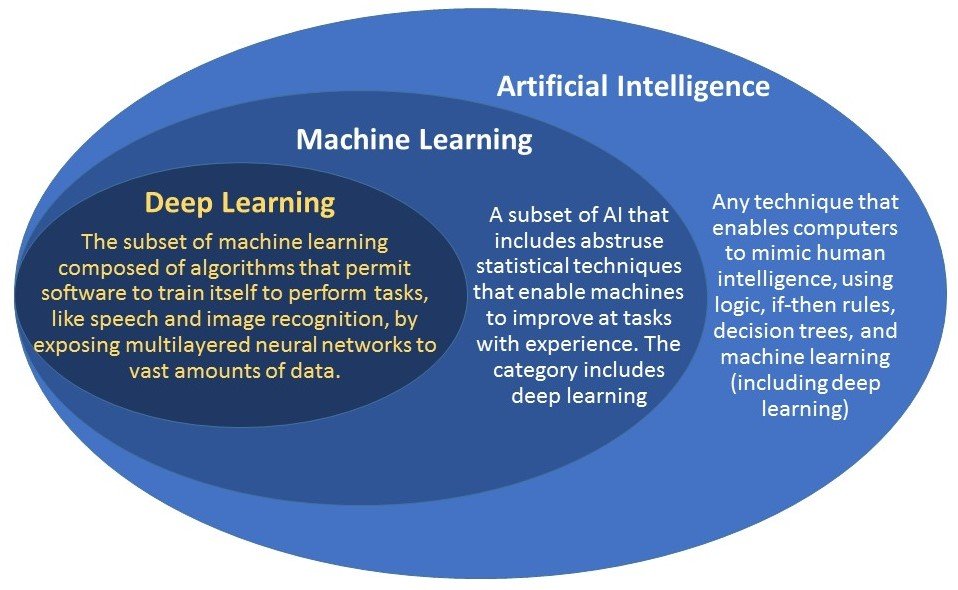
You can think of artificial intelligence (AI), machine learning and deep learning as a set of a matryoshka doll, also known as a Russian nesting doll. Deep learning is a subset of machine learning, which is a subset of AI. Read More
A Handy Way to Think About Machine Learning
I often find explanations of machine learning either too complex or overly simplistic. I’ve recently had some luck using a simple frame for explaining it to people in person. Let’s see if I can quickly capture it in this post. Read More
Understanding Generative Adversarial Networks (GANs)
Yann LeCun described it as “the most interesting idea in the last 10 years in Machine Learning”. Of course, such a compliment coming from such a prominent researcher in the deep learning area is always a great advertisement for the subject we are talking about! And, indeed, Generative Adversarial Networks (GANs for short) have had a huge success since they were introduced in 2014 by Ian J. Goodfellow and co-authors in the article Generative Adversarial Nets. Read More
