
No, you’re not imaging things: Social media is getting more extreme—and there’s a scientific reason for that.
A new study out of Yale University suggests the reason that your Facebook and Twitter feeds are now laden with scathing political diatribes and lengthy personal commentary is because we’ve been subtly trained to post those, through a system of rewards powered by “likes” and “shares.” Simply put, because content with “expressions of moral outrage” is more popular, we publish more of it. Read More
Tag Archives: Machine Learning
Machine Learning Won’t Solve Natural Language Understanding
In the early 1990s a statistical revolution overtook artificial intelligence (AI) by a storm – a revolution that culminated by the 2000’s in the triumphant return of neural networks with their modern-day deep learning (DL) reincarnation. This empiricist turn engulfed all subfields of AI although the most controversial employment of this technology has been in natural language processing (NLP) – a subfield of AI that has proven to be a lot more difficult than any of the AI pioneers had imagined. The widespread use of data-driven empirical methods in NLP has the following genesis: the failure of the symbolic and logical methods to produce scalable NLP systems after three decades of supremacy led to the rise of what are called empirical methods in NLP (EMNLP) – a phrase that I use here to collectively refer to data-driven, corpus-based, statistical and machine learning (ML) methods.
The motivation behind this shift to empiricism was quite simple: until we gain some insights in how language works and how language is related to our knowledge of the world we talk about in ordinary spoken language, empirical and data-driven methods might be useful in building some practical text processing applications. As Kenneth Church, one of the pioneers of EMNLP explains, the advocates of the data-driven and statistical approaches to NLP were interested in solving simple language tasks – the motivation was never to suggest that this is how language works, but that “it is better to do something simple than nothing at all”. The cry of the day was: “let’s go pick up some low-hanging fruit”. In a must-read essay appropriately entitled “A Pendulum Swung Too Far”, however, Church (2007) argues that the motivation of this shift have been grossly misunderstood. As McShane (2017) also notes, subsequent generations misunderstood this empirical trend that was motivated by finding practical solutions to simple tasks by assuming that this Probably Approximately Correct (PAC) paradigm will scale into full natural language understanding (NLU). As she puts it: “How these beliefs attained quasi-axiomatic status among the NLP community is a fascinating question, answered in part by one of Church’s observations: that recent and current generations of NLPers have received an insufficiently broad education in linguistics and the history of NLP and, therefore, lack the impetus to even scratch that surface.”
This misguided trend has resulted, in our opinion, in an unfortunate state of affairs: an insistence on building NLP systems using ‘large language models’ (LLM) that require massive computing power in a futile attempt at trying to approximate the infinite object we call natural language by trying to memorize massive amounts of data. In our opinion this pseudo-scientific method is not only a waste of time and resources, but it is corrupting a generation of young scientists by luring them into thinking that language is just data – a path that will only lead to disappointments and, worse yet, to hampering any real progress in natural language understanding (NLU). Instead, we argue that it is time to re-think our approach to NLU work since we are convinced that the ‘big data’ approach to NLU is not only psychologically, cognitively, and even computationally implausible, but, and as we will show here, this blind data-driven approach to NLU is also theoretically and technically flawed. Read More
Amazon Fresh grocery store: Meet Just Walk Out shopping
For the first time, Just Walk Out technology is available in a new full-size Amazon Fresh grocery store.
Now customers can save time shopping for groceries by skipping the checkout line with the launch of our new Amazon Fresh grocery store with Just Walk Out shopping, now open in The Marketplace at Factoria in Bellevue, Washington.
Using a combination of overhead cameras equipped with computer vision to identify items customers put in their cart, weight-detecting sensors to log whenever they move items from or back to store shelves, and back-end systems to track the data and manage inventory, Amazon is proving out the scalability of the Amazon Fresh concept. Read More
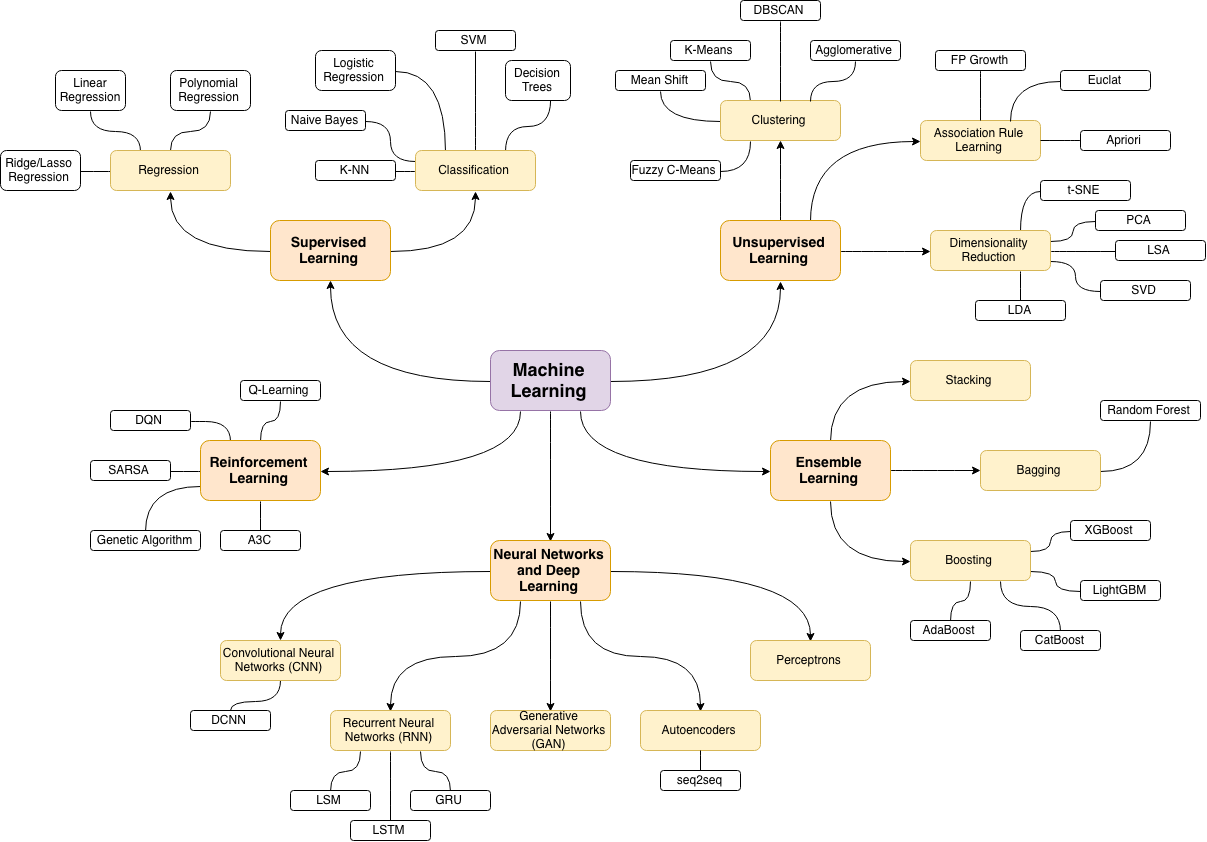
Machine Learning Roadmap

Machine Learning Systems Design
… Machine Learning Systems Design is a freely-available course from Stanford taught by Chip Huyen which aims to give you a toolkit for designing, deploying, and managing practical machine learning systems. Here’s what the course website has to say about what machine learning systems design is, in a succinct manner:
Machine learning systems design is the process of defining the software architecture, infrastructure, algorithms, and data for a machine learning system to satisfy specified requirements.
Besides the course material on the website, Chip has written these related machine learning systems design notes available on her website; there may be overlap between this material and that which is on the course website, as I have not done a thorough comparison. Read More
Four Deep Learning Papers to Read in April 2021
From Meta-Gradients to Clockwork VAEs, a Global Workspace Theory for Neural Networks and the Edge of Training Stability
Welcome to the April edition of the ‚Machine-Learning-Collage‘ series, where I provide an overview of the different Deep Learning research streams. So what is this series about? Simply put, I draft one-slide visual summaries of one of my favourite recent papers. Every single week. At the end of the month all of the visual collages are collected in a summary blog post. Thereby, I hope to give you a visual and intuitive deep dive into some of the coolest trends. So without further ado: Here are my four favourite papers that I read in March 2021 and why I believe them to be important for the future of Deep Learning. Read More
Why machine learning struggles with causality
When you look at a baseball player hitting the ball, you can make inferences about causal relations between different elements. For instance, you can see the bat and the baseball player’s arm moving in unison, but you also know that it is the player’s arm causing the bat’s movement and not the other way around. You also don’t need to be told that the bat is causing the sudden change in the ball’s direction.
Likewise, you can think about counterfactuals, such as what would happen if the ball flew a bit higher and didn’t hit the bat.
Such inferences come to us humans intuitively. We learn them at a very early age, without being explicitly instructed by anyone and just by observing the world. But for machine learning algorithms, which have managed to outperform humans in complicated tasks such as Go and chess, causality remains a challenge. Machine learning algorithms, especially deep neural networks, are especially good at ferreting out subtle patterns in huge sets of data. They can transcribe audio in real time, label thousands of images and video frames per second, and examine X-ray and MRI scans for cancerous patterns. But they struggle to make simple causal inferences like the ones we just saw in the baseball example above.
In a paper titled “Towards Causal Representation Learning,” researchers at the Max Planck Institute for Intelligent Systems, the Montreal Institute for Learning Algorithms (Mila), and Google Research discuss the challenges arising from the lack of causal representations in machine learning models and provide directions for creating artificial intelligence systems that can learn causal representations. Read More
Homemade Machine Learning
The purpose of this repository is not to implement machine learning algorithms by using 3rd party library one-liners but rather to practice implementing these algorithms from scratch and get better understanding of the mathematics behind each algorithm. That’s why all algorithms implementations are called “homemade” and not intended to be used for production.
Class Imbalance: Random Sampling and Data Augmentation with Imbalanced-Learn
An exploration of the class imbalance problem, the accuracy paradox and some techniques to solve this problem by using the Imbalanced-Learn library.
One of the challenges that arise when developing machine learning models for classification is class imbalance. Most of the machine learning algorithms for classification were developed assuming balanced classes however, in real life it is not common to have properly balanced data. Due to this, various alternatives have been proposed to address this problem as well as tools to apply these solutions. Such is the case imbalanced-learn [1], a python library that implements the most relevant algorithms to tackle the problem of class imbalance.
In this blog we are going to see what class imbalance is, the problem of implementing accuracy as a metric for unbalanced classes, what random under-sampling and random over-sampling is and imbalanced-learn as an alternative tool to address the class imbalance problem in an appropriate way. Read More
